I was recently reminded of the fact that people use the term “peer-to-peer” to mean a variety of different things. That can make conversations on the topic difficult, as with any situation where you assume you have common ground, only to discover that is not the case.
In this interlude, I want to – really quite quickly – disambiguate some things, as a kind of reference for future conversations. You don’t need to agree with me. Though if that’s the case, I’d be interested to hear about it!

Figure: “Fog city” by Nick-K (Nikos Koutoulas) is licensed under CC BY-ND 2.0
Protocols
The most basic source of misunderstanding I encounter regards what exactly constitutes a protocol, never mind if it’s peer-to-peer or not.
The term is derived from the common, non-computer-science usage of the word, which some dictionaries define as e.g. “the forms of ceremony and etiquette observed by diplomats and heads of state”, or “a code of proper conduct”.
Applied to the realm of computing, this describes how components in a computer, or computers in a network discover and introduce themselves to each other, request or respond to requests for services, etc.
Taken a little into the more abstract realm than that, it implies that otherwise independent actors (processes, computers, etc.) maintain state on their understanding of a mutual exchange, to the extent that such state is necessary. They then send messages according to the rules of the protocol and their internal state, and update said state on receipt of messages.
It’s arguable that a protocol then consists of state machines and messages that correspond to state transition events. So far, most people I’ve encountered share this view more or less.
Where things drift apart is the question of the specifics of how these messages get exchanged. I encounter a lot of folk for whom this is not a relevant question. And from the perspective that the validity of the protocol is independent of such issues, they are entirely correct. But in practice, computers do not know how to exchange messages unless you tell them.
I spend a lot of my formative software engineering years reading requests for comments, the documents effectively outlining how to make the Internet work. And in a majority of cases, these documents either specify very precisely how to exchange messages, explicitly refer to a previously standardized way, or at minimum outline the expectations they have on such methods.
My expectations of discussions on networking protocols is that these considerations are included. And that is because not every lower-level networking protocol is created equal.
If, for example, your assumption is that messages can be JSON-encoded and transported over HTTP, then that’s fair in and of itself. But it’s also clear to me on the one hand that you’re missing a discussion of HTTP endpoints, methods and status codes for a complete specification. And on the other hand, it’s also clear to me that you do not expect your network nodes to be behind NATs.
Peer
To be fair, the above is fine in principle. But when we’re discussing P2P networks, it also becomes necessary to clarify this a little. That’s especially the case today, where phrases such as “peer-to-peer lending” are flung around.
The suggestion in this phrase, as in the idea of P2P networks, is that the exchange is entered into as equals.
In practice, the phrase was coined to distinguish it from the client-server principle, in which clients make requests to servers, and servers respond to them. In peer-to-peer networks, either participant can make a request or respond to one.
The term is therefore also mired in the history of thin and fat clients. Throughout history of networked computers, the role of the client has shrunk and receded, always depending on whether it was more costly to process data or transfer it.
Without going into too many specifics here, however, it was always clear that servers exist to serve more than one client, whereas clients are effective “user agents” and represent a single user. The upshot of this is that servers were always meant to be more powerful in one way or another.
With dial-up internet and NATs, and all that kind of thing, there is a second angle to this: servers must be reachable, so have an address (IP or otherwise) that any eligible client can resolve and route to. Clients, by contrast, do not need this.
In a P2P setting where each node may or may not act as a user agent, this is a crucial consideration. Does the node have such a “public” address or not? If yes, is it perhaps more of a server in effect? If not, should it be classified more as a client?
If you want to make a peer-to-peer network truly a network of peers, such distinctions must not matter. That is, you must find ways to directly connect peers irrespective of whether they own a “public” address. Methods such as e.g. STUN or similar would achieve this. Arguably if you do not, then your network is not peer-to-peer.
Note: the “peer” I’m referring to in the title of this blog is explicitly a TCP “peer”; the message “connection reset by peer” corresponds to receiving a TCP RST packet which resets the connection. The “peer” here is the remote end of the TCP connection.
Distribution vs Decentralization
The above view goes right back to Paul Baran’s distinction of distributed vs. decentralized networks, as expressed in his 1964 memorandum On Distributed Computing for the RAND organization.
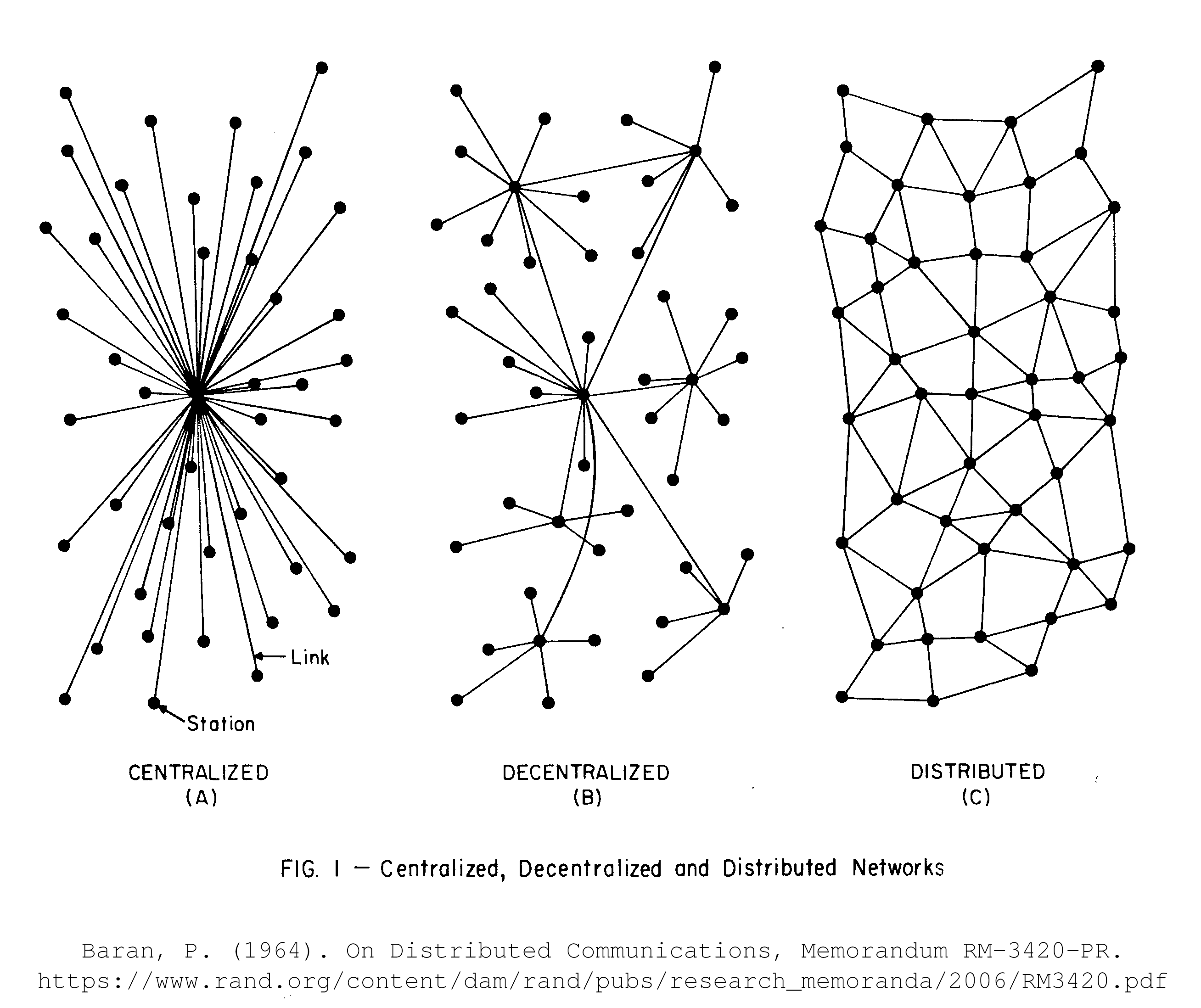
The diagram above shows clearly that a distributed network is only achievable if any peer can directly engage with any other peer. If there are peers that (by design, not happenstance) form communications hubs, at best the network is decentralized.
Distribution is a necessary requirement for peer-to-peer networks. It’s still possible for some peers to take on different roles, but if their distinction is based on their limited or enhanced ability to facilitate basic connectivity, then the network degrades to decentralization.
Pure P2P
In some classifications of P2P networks, there is a distinction between so-called pure and hybrid P2P networks. There may also be mention of central P2P networks.
The description above essentially describes pure P2P networks. Central P2P networks have peers engage directly with each other in some forms of communication, but initiate a conversation via a central instance. Hybrid P2P networks… well this is where the fun starts.
Hybrid P2P
As the name implies, hybrid P2P networks combine some parts of P2P with some parts of, well, other models. They’re not central, though, in that there is no single central entity which the network relies on.
A loose classification would be that there are some nodes in the network that take on a more central role, but they’re not predetermined. This definition probably works across all interpretations of hybrid networks.
But there are stricter classifications which suggest that a network topology is derived from this. One such suggestion essentially divides the roles of nodes into those forming a pure P2P network in their self-organization. A common term for these nodes is “super nodes” or “super peers”, but the term has issues I’ll get into below.
In this view, super nodes provide services to any other node in the network, the essence of which is that most (leaf) nodes take on a client role, whereas the super nodes take on a server role. The peer-to-peer part here consists predominantly of the fact that super nodes self-organize instead of being managed by a service provider.
This model of hybrid P2P networks is strongly associated with blockchain. There are many people who treat blockchain as essentially peer-to-peer, which is true only for some interpretations of what it means to be a peer (see above). On the basis of that interpretation, a blockchain is essentially a distributed database managed by all participating super nodes (or full nodes in blockchain parlance). By contrast, any other nodes (light nodes in blockchain terms) are the client nodes.
I do not share this interpretation.
I do not share it for two reasons: a) it is historically inaccurate, and b) it is unnecessarily restrictive.
First off, it is unnecessarily restrictive because it immediately pushes the notion of a peer-to-peer network away from distribution towards decentralization, which cannot provide the same affordances to leaf nodes acting as user agents as a distributed network can. Refer to Baran for well-outlined reasons.
But this interpretation is also historically inaccurate. And this is both a more personal reason, and one that leads on to a much stronger argument for challenging this line of thinking.
Skype as a Hybrid P2P Network
Enter Skype. Or Joost. Or KaZaA. Or Joltid.
You probably haven’t heard of some of these.
All are ventures started by Janus Friis and Niklas Zennström, and all employ peer-to-peer technology. In particular, they employ technology by Joltid, a company they held to manage this.
I joined Joost in 2006, when it was still a startup in stealth mode. Joost provided peer-to-peer video streaming of a quality near to digital TV (just below DVD), at a time when YouTube was limited to a few minutes of low resolution cat videos. The product was based on Joltid’s P2P stack1.
After its launch, we moved from on-demand video to live streaming. In 2008, we streamed March Madness live to an audience of about a thousand users in an early beta.
In order to do this work, we had to understand Joltid’s P2P software, and not merely use it. And as it so happened in our team numbering a handful, that task fell to me. I remember I took way longer than anyone wanted to break through, but eventually produced a detailed document on this software’s inner workings that helped us make some crucial decisions in how to approach live streaming a little differently.
The point of this anecdote is, at this time, the term hybrid P2P term meant something entirely different from the blockchain-centric view above. What’s more, it was the same more flexible definition I gave above: merely that some nodes take on extra roles in an otherwise fully distributed network.
Of course, I signed an NDA back then. Of course, the NDA has expired by now. Of course, I don’t remember every detail from a decade and a half ago. However, there is one specific thing I recall very clearly, and there is a public record of it:
On Thursday, 16th August 2007, the Skype peer-to-peer network became unstable and suffered a critical disruption. The disruption was triggered by a massive restart of our users’ computers across the globe within a very short time frame as they re-booted after receiving a routine set of patches through Windows Update.
The high number of restarts affected Skype’s network resources. This caused a flood of log-in requests, which, combined with the lack of peer-to-peer network resources, prompted a chain reaction that had a critical impact.
The crux here is this: personal computers restarting meant Skype nodes going offline for a while.
How is that possible? It’s possible because in what is otherwise a pure, i.e. distributed P2P network, some nodes took on special roles, which turned them into “super nodes”. This construction of the P2P network spawned that term, and made Skype both special and hybrid.
These nodes were peers in (almost) every sense: they did not necessarily have public IP addresses, they did not run in data centres. The only difference is that the Skype network voted for them to take on a special organizing role, providing more persistence to the network’s index. My document was to a large part concerned with what criteria made a node eligible, and how the voting progressed, none of which is particularly relevant here.
What the public discussion of the events did not refer to, however, is the role Joost played in any of this.
You see, there is a bootstrapping problem in this. How can a newly installed Skype instance know which super nodes to contact for indexing – or which nodes at all, period? It turns out that for this purpose, Skype was running two dedicated super nodes, as a way to bootstrap new nodes (over time, Skype added more discovery methods for super nodes).
So when you started your Skype software, it would contact some of the last known super nodes instead of these dedicated two. Only when that list could not be reached would the dedicated super nodes be contact again, which in practice was – never.
In fact, this pure P2P approach worked so well that Skype simply stopped operating those two dedicated super nodes. But when all non-dedicated, elected super nodes restarted due to a Windows update, suddenly there was demand again for dedicated nodes that couldn’t be reached.
Enter a phone call to Joost. We were running dedicated super nodes for our video network, and our video network no longer needed them full-time, just like the Skype one - we just happened to keep operating them. With a bit of a configuration jiggle and a recompile, our dedicated super nodes went live again pretending to be Skype’s, and the Skype network could rebuild.
This long story should provide some key insights into hybrid P2P networks:
- In 2007, they had central components for bootstrapping the system.
- They typically operated in a pure P2P mode.
- In no way did “light” nodes exist that merely connected to “full” nodes, by whichever terminology.
The thing that frustrates me here isn’t that terms change their meanings. I don’t massively care what is taught nowadays in universities as “hybrid” P2P networks.
What I do care about, and passionately so, is that this rewrite of history means that modern-day students cannot even conceive of how amazingly peer-to-peer (in every sense) the Skype network was, because they lack the terminology to describe it. And if you can’t conceive of something, it becomes that much harder to build anything like it again.
P2P vs. CDNs
As it so happens, a few days after writing this text, there was a discussion on hacker news about P2P vs CDNs, so I’ve updated this text with the section you’re reading now. In it, people claiming to have built content delivery networks (CDNs) claim there is little advantage for using P2P, and provide that as a reason why P2P is not used much.
This is wrong.
First, this leads into an interesting side track, which I’ll cover only very briefly: just because P2P networks have often been used for file sharing, it does not mean that file sharing is the only reason for connecting peers directly. Skype serves as a great example for a use case where file sharing is possible, but also the least prominent usage.
But when comparing to CDNs, file sharing fits naturally. In both instances, there is an authoritative source for some piece of content. Then, user-agents do not access this authoritative source directly, but contact other nodes in a network which have cached it. In this abstract sense, the two operate in exactly the same way.
The argument for CDNs in the discussion is about popularity of content. Popular content will get cached at many P2P nodes, but for the “long tail” of less popular content, there may not be any peer caching it.
This argument presupposes things about the workings of P2P networks that may have historically been true, but need not be true in any way. First, it assumes that P2P caches are only populated when the node’s user requests content, which need not be true at all.
But second, and more critically so, it lacks imagination.
See, CDNs fulfil two functions: one is the caching of content. The other is discovery.
By contrast, the roles of discovery and caching are disjunct in P2P networks. That is, “the network” provides some indexing facilities – maybe using super nodes –, while individual nodes decide to cache content. Any participant in the network contributes to discovery, and only some participants provide storage.
There is no reason whatsoever why one cannot pay caching node providers for storing long tail content, while leaving discovery outside of their immediate control.
Except, of course, that it is in CDN provider’s interest to act as a gatekeeper. That is an economically highly effective position to achieve and maintain, so naturally a model that would deliberately give this up is anathema to their business interests.
P2P networks aren’t widely adopted because they fail to deliver the same quality of service. They’re not widely adopted because nobody has built them to guarantee the same quality of service yet (by modelling separate node roles).
Conclusion
In summary, when I engage in conversations on P2P networks, I carry with me a number of assumptions that are not commonly shared. It will sometimes make it difficult to explain things, also in connection with the Interpeer Project.
In summary, I suppose it’s fair to say that I take the following view:
- I consider the point of peer-to-peer networks to provide resilience and fairness.
- Resilience refers to distribution as Baran argues for it.
- Fairness refers to a node being able to represent a user’s needs directly.
- Both require nodes to be able to directly connect to each other, in a pure P2P fashion; consequently, if some nodes must mediate communications between others by inherent design, the network fails at being resilient or fair.
- This does not preclude nodes from taking on special roles within the network. The generalized view of the above is that any special role a node enters must not be by prior design or otherwise create a fixed hierarchy or resilience and fairness are at risk.
- It’s still P2P if node operators are paid for having their node(s) fulfil a particular role.
-
If it weren’t a little tragic, it would be kind of funny how many “world’s first P2P video streaming” products I’ve seen announced in the years since. ↩︎